Zo verbind je met je eigen LLM-server: Handleiding voor maatwerk code
In mijn eerdere blog legde ik uit hoe ik een homelab-server heb gebouwd. Op de server plaats ik de code voor mijn Django-applicatie en heb ik het model Qwen2.5-14B gedownload, zodat dit altijd beschikbaar is wanneer nodig. Nu de server klaar is, wordt het tijd om er eenvoudig verbinding mee te maken zodat ik kan communiceren met mijn lokale AI-model.
In deze blog laat ik stap voor stap zien hoe ik het AI-model Qwen2.5-14B lokaal heb geïnstalleerd en geïntegreerd in een simpele desktop-applicatie. Ik leg ook uit welke keuzes ik heb gemaakt en waarom.
Waarom lokaal en waarom Qwen2.5-14B?
Voor mijn project wilde ik volledige controle, privacy en stabiliteit. Een lokaal draaiend model betekent geen afhankelijkheid van externe Cloudproviders, en dit geeft me ook de vrijheid om eenvoudig te testen en snel aanpassingen te doen.
Ik heb gekozen voor Qwen2.5-14B, omdat dit model een uitstekende balans biedt tussen prestaties en hardware-eisen. Het model is krachtig genoeg om complexe contextuele vragen nauwkeurig te beantwoorden, terwijl het toch efficiënt genoeg is voor lokale implementatie. Dit past prima bij mijn RTX 3060 GPU.
Project highlights:
- Lokaal AI-model (Qwen2.5-14B) op RTX 3060
- Gecontaineriseerd met Docker (GPU-acceleratie)
- Desktop-applicatie (Django UI)
- Modulaire architectuur: spraak, beeldherkenning, chatopslag
- Geen internetverbinding vereist tijdens gebruik
- 20+ tokens/sec
Installatie en configuratie (in hoofdlijnen)
Voordat je een LLM-model kunt installeren, zijn er een paar voorbereidende stappen nodig om ervoor te zorgen dat alles netjes en overzichtelijk blijft. Hieronder geef ik een korte uitleg over mijn mappenstructuur en hoe je via Hugging Face gemakkelijk een lokaal LLM-model kunt downloaden.
Voor een schone installatie maak ik gebruik van twee isolatielagen: een Python virtual environment voor het installeren van Hugging Face (om conflicten met bestaande Python packages te voorkomen) en Docker voor het draaien van het project zelf.
Het voordeel van Docker is dat programma’s in een afgesloten container draaien, gescheiden van je besturingssysteem, waardoor conflicten tussen verschillende projecten worden voorkomen.
- **Structuur opzetten:** Maak een overzichtelijke mapstructuur aan in je server:
mkdir -p ~/huggingface_hub
mkdir -p ~/projects/mikifit/models
- **Virtuele omgeving:** Maak een virtuele Python-omgeving aan om conflicten met andere pakketten te voorkomen. Zorg ervoor dat je in je virtual environment bent als je Hugging Face gaat gebruiken (je herkent dat je in je virtual environment bent aan (.env)):
python3 -m venv .env
source .env/bin/activate
pip install huggingface_hub

Foto 1: aanmaken en configureren van je virtual env.
- **Model downloaden:** Download het model met Hugging Face CLI naar je lokale map:
huggingface-cli download bartowski/Qwen2.5-14B-Instruct-GGUF Qwen2.5-14B-Instruct-Q5_K_M.gguf –local-dir ~/projects/mikifit/models
Links naar het model en installatieguide:
- **Model:** https://huggingface.co/bartowski/Qwen2.5-14B-Instruct-GGUF/blob/main/Qwen2.5-14B-Instruct-Q5_K_M.gguf
- **HuggingFace installatieguide:** https://huggingface.co/docs/huggingface_hub/installation#check-installation
Testen van setup
Nadat de download compleet is, test of alles goed is aangemaakt door in je virtual environment de volgende command uit te voeren:
python -c “from huggingface_hub import model_info; print(model_info(‘gpt2’))”
Je zou dan de output moeten krijgen zoals omschreven in foto 2.

Foto 2: klein gedeelte van de uitvoer dat laat zien dat ik huggingface_hub goed heb geïnstalleerd.

Foto 3: model wordt gedownload naar de juiste map.
Docker Compose configureren voor lokale AI-server
Om het draaien van het AI-model eenvoudig te houden, gebruik ik Docker Compose. Hieronder beschrijf ik stap voor stap hoe je dit opzet en controleert:
1. **Docker installeren:**
Zorg dat je Docker geïnstalleerd hebt. Volg hiervoor de officiële instructies:
2. **NVIDIA GPU ondersteuning:**
Installeer de NVIDIA Container Toolkit zodat Docker gebruik kan maken van GPU-acceleratie:
3. **Docker Compose configuratie maken:**
Ga naar de map van je project en maak daar een docker-compose.yml bestand aan:
- cd /home/projects/mikifit
- nano docker-compose.yml
Voeg vervolgens onderstaande configuratie toe en sla het bestand op. Let hierbij op dat je onder het kopje ports de IP-adres invoert van je server:
services:
llama-server:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
runtime: nvidia
restart: unless-stopped
ports:
– [Plaats hier je IP-adres]:8080:8080″
volumes:
– ~/projects/mikifit/models:/models:ro
environment:
CUDA_VISIBLE_DEVICES: 0
command: >
–model /models/Qwen2.5-14B-Instruct-Q5_K_M.gguf
–host 0.0.0.0
–port 8080
–n-gpu-layers 35
–ctx-size 4096
4. **Docker container starten:**
Start nu je Docker container met de command:
docker compose up -d
5. **Controleren of alles werkt:**
Controleer of je AI-server draait met:
docker compose logs -f
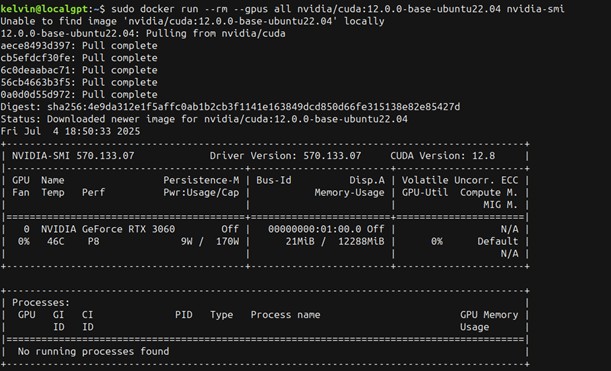
Foto 4: bevestiging dat alles goed geïnstalleerd is.
Start je systeem opnieuw op en start je docker container met docker compose up -d. Controleer daarna of je docker container draait: docker compose logs -f.


Foto 5: LLM draait lokaal op mijn server.
Je server is nu klaar voor gebruik. Hiermee heb je een lokaal draaiend AI-model met GPU-ondersteuning, volledig gecontaineriseerd.
Django Desktop Applicatie: Van AI-server naar werkende demo
Nu het AI-model lokaal draait, is het tijd om er een praktische applicatie omheen te bouwen. Ik heb gekozen voor een desktop-app omdat dit veel eenvoudiger te demonstreren is en ik geen zorgen heb over webhosting of beveiligingsproblemen van een publieke server.
Ik heb gekozen voor Python als ontwikkeltaal omdat het breed wordt ingezet in AI/ML, uitgebreide bibliotheken heeft (zoals Hugging Face, PyTorch) en het snel prototypen mogelijk maakt.
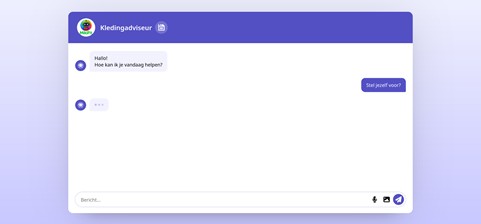
Werking in het kort:
Mijn desktopapplicatie maakt gebruik van een eenvoudige Django UI waarin je tekst invoert. Deze tekst wordt via een lokale API doorgestuurd naar het draaiende Qwen2.5-model via een voorgeprogrammeerd IP-adres. Dit zorgt voor snelle en veilige verwerking van de data zonder dat gegevens extern verwerkt hoeven worden.
Geplande uitbreidingen:
Voor extra gebruiksgemak ben ik bezig met de implementatie van:
- Spraakherkenning (STT) & Tekst-naar-spraak (TTS): Voor handsfree interactie
- OpenCV2 integratie: Voor toekomstige beeldverwerking
- Opslaan van chatberichten: Filtering en moderatie van AI-output
Foto 6: Screenshot van mijn lokale LLM chatbox applicatie
Wat ik tot nu toe geleerd heb:
- AI is het krachtigst bij gestructureerde, herhaalbare taken met duidelijke input-output verwachtingen
- Lokale installatie biedt maximale controle, privacy en consistente performance
- Eenvoudige oplossingen werken beter voor demonstraties dan complexe systemen
- De waarde van een modulaire opbouw voor toekomstige uitbreidingen
Volgende stappen:
Met deze basis ga ik nu verder met het verfijnen van de features en het toepassen van deze kennis op pentesting en geavanceerde systeemanalyses.
De volledige broncode en installatie-instructies vind je op mijn GitHub. Daar kun je het project zelf uitproberen en aanpassen naar eigen wensen.
Afsluiter:
In minder dan een dag heb ik het Qwen2.5-14B-instruct model werkend gekregen op mijn eigen RTX 3060, volledig gecontaineriseerd via Docker en met GPU-support.
- Performance: 20 tokens/sec (gemeten in server logs)
- Setup: Docker Compose, llama.cpp CUDA-image, lokaal GGUF-model
- Toepassing: Klaar voor demo’s, API-integratie of verdere uitbreiding
Met dit project toon ik aan dat ik zelfstandig complexe technische oplossingen kan bouwen, documenteren en praktisch toepassen—skills die direct inzetbaar zijn in elke moderne IT-omgeving.
Volgende stap: eigen Python-code/applicatie bouwen die deze API aanspreekt.
Kelvin
Hallo! Ik ben een IT-professional in wording, met een fascinatie voor technologie die al in mijn tienerjaren begon. Waar anderen op zoek waren naar cheatcodes, wilde ik begrijpen hoe alles werkt en was ik al vroeg bezig met het uit elkaar halen van oud apparatuur. Mijn avontuur begon met het rooten van smartphones en het installeren van Linux op oude computers. Het optimaliseren en vernieuwen van oud apparatuur gaf me veel voldoening en technisch inzicht. Door mijn ervaringen heb ik besloten om uiteindelijk de stap te wagen en me volledig op tech te focussen.

